Here it goes, so i don't lose it. Also attached to the issue.
Still, more work to come in MAHOUT-797, although not tremendously a lot...
Thursday, September 8, 2011
Thursday, September 1, 2011
#Mahout #MapReduce #SSVD version gets power iterations, fixes
I have been working on MAHOUT-796 this week (current work is in https://github.com/dlyubimov/mahout-commits/tree/MAHOUT-796).
Nathan Halko pointed to me that power iterations in practice improve precision and reduce noise.
After a little discussion, that's the route we went :
Bug fixes
Nathan Halko pointed to me that power iterations in practice improve precision and reduce noise.
After a little discussion, that's the route we went :
Original formula
\[\mathbf{Q}=\mbox{qr}\left[\left(\mathbf{AA^{\top}}\right)^q\mathbf{A}\boldsymbol{\Omega}\right].\mathbf{Q},\]
\[\mathbf{B}=\mathbf{Q}^{\top}\mathbf{A}.\]
Modified version
\[\mathbf{Y}=\mathbf{A}\boldsymbol{\Omega},\]
\[\mathbf{B}_{0}=\left[\mbox{qr}\left(\mathbf{Y}\right).\mathbf{Q}\right]^{\top}\mathbf{A},\]
\[\mathbf{B}_{i}=\left[\mbox{qr}\left(\mathbf{AB}_{i-1}^{\top}\right).\mathbf{Q}\right]^{\top}\mathbf{A},\, i\in\left[1..q\right].\]
Notation \(\mbox{qr}\left(\cdot\right).\mathbf{Q}\) means "compute QR decomposition of the argument and retain Q as a result".
Current combination of QJob and BtJob is essentially producing \(\mathbf{B}_{0}^{\top}=\mathbf{A}^{\top}\mbox{qr}\left(\mathbf{A}\boldsymbol{\Omega}\right).\mathbf{Q}\). Intermediate QJob results are QR blocks, not a final Q, so QJob is not terribly meaningful without BtJob.
The task boils down to figuring out alternative pipeline modifications necessary to produce \(\mathbf{B}_{i}^{\top}\). After that, algorithm proceeds as before with assumption of \[\mathbf{B}\equiv\mathbf{B}_{q}.\]
The existing processing will be equivalent to \({q}=0\).
\(\mathbf{B}_{i}\) pipeline (some new code)
\(\mathbf{B}_{i}\) pipeline produces \[\mathbf{B}_{i}^{\top}=\mathbf{A}^{\top}\mbox{qr}\left(\mathbf{A}\mathbf{B}^{\top}\right).\mathbf{Q}.\]
this is very similar to \(\mathbf{B}_{0}\) pipeline with specfics being full multiplication of \(\mathbf{A}\mathbf{B}^{\top}\) in the first job and first pass qr pushdown to the reducer of the first job:
- map1 : \(\mathbf{A}\mathbf{B}^{\top}\) outer products are produced
- combiner1 : presumming outer products of \(\mathbf{A}\mathbf{B}^{\top}\).
- reducer1 finalizes summing up outer products of \(\mathbf{A}\mathbf{B}^{\top}\) and starts \(\mbox{qrFirstPass}\left(\mathbf{A}\mathbf{B}^{\top}\right)\to\mbox{qr blocks}\). (partitioning must be done by A block # it seems).
- mapper2, combiner2, reducer2 proceed exactly as mapper2, combiner2, reducer2 in B pipeline and output final \(\mathbf{B}_{i}^{\top}\) with blocks corresponding to initial splits of A input.
Thus, this pipeline is 2 MR jobs with 2 sorts (map1 + combiner1 + shuffle and sort + reducer1 + map2 + combiner2 + shuffle and sort + reducer2).
Integration of Cholesky trick route for computing power iterations
Ted Dunning pointed out that the whole B pipeline could avoid QR step.
When power iterations are concened, note that whatever route is chosen to calculate \(\mathbf{B}_{i}=g\left(\mathbf{Y}_{i}\right)\), mathematically it should still be valid \(\forall i\in\left[0..q\right]\) for as long as we assume
\[\mathbf{Y}_{0}=\mathbf{A}\boldsymbol{\Omega}, i=0;\]
\[\mathbf{Y}_{i}=\mathbf{A}\mathbf{B}_{i-1}^{\top}, i>{0}.\]
So, if Cholesky trick allows to produce \(\mathbf{B}_{0}\) efficiently, I see no reason why it could not be applied to producing the \(\mathbf{B}_{i}\).
I will be pursuing MR option of running Cholesky decompositon of \(\mathbf{Y}^{\top}\mathbf{Y}\) in MAHOUT-797.
If that holds, then power iterations with Cholesky decomposition will likely be similar.
\(\mathbf{LL}^{\top}=\mathbf{Y}^{\top}\mathbf{Y}=\mathbf{R}^{\top}\mathbf{R}\Rightarrow\) we know how to compute \(\mathbf{R}\);
\[\mathbf{B}_{i}=\left(\mathbf{R}^{-1}\right)^{\top}\mathbf{Y_{i}}^{\top}\mathbf{A};\]
\[\mathbf{Y}_{0}=\mathbf{A}\boldsymbol{\Omega}, i=0;\]
\[\mathbf{Y}_{i}=\mathbf{A}\mathbf{B}_{i-1}^{\top}, i>{0}.\]
Tests
Tests with local MR QR-based solver seem to be encouraging. There's clear improvement on precision.
With surrogate random input with predefined singular values 10,4,1,(0.1...), toy input 2000x1000 and k=3,p=10 I seem to be getting improvement after just one additional power iteration:
q=0:
--SSVD solver singular values:
svs: 9.998472 3.993542 0.990456 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000
svs: 9.998472 3.993542 0.990456 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000
q=1: (+2 more MR sequential steps):
--SSVD solver singular values:
svs: 10.000000 4.000000 0.999999 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000
--SSVD solver singular values:
svs: 10.000000 4.000000 0.999999 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000 0.100000
After some tests and cleanup, I guess it is going to become a commit really soon.
In addition to all this, MAHOUT-796 branch gets a lot of bug fixes (in particular, better handling sparse inputs which seemed to have still been broken in current version).
Saturday, June 4, 2011
John #Canny's function #summarizer formulae #Pig #MapReduce
Credit for the idea to Ted Dunning, but I wanted to log the final formulae set i used for MapReduce and Pig implementation of these kind of summarizers for my future reference. Here it goes.
Adaptation
\[s\left(t\right)=ke^{-t}-\left(k-1\right)e^{-\frac{k}{k-1}t},\, k>1. \]
This $s\left(t\right)$ (which Ted Dunning calls 'Canny's filter') has desirable properties of $s'\left(0\right)=0$ and $s\left(0\right)=1 $.
In our case, it takes form of
\[y\left(x\right)=ke^{-x/\alpha}-\left(k-1\right)e^{-kx/\alpha\left(k-1\right)} \]
Given margin $m$ and decay time $\Delta t$ , so that
\[y\left(\Delta t\right)=m,\]
solving for $\alpha$, we get estimate for $\alpha$ assuming margin $m\ll1$ as
\[\alpha\approx-\frac{\Delta t}{\ln\left(m/k\right)}.\]
I take $\Delta t$ as constructor input with good default values of $k=4$ and $m=0.01$.
Iterative update $t_{n+1}\geq t_{n}$
\[\begin{cases}\begin{cases}\pi_{0}=1,\,\nu_{0}=1,\\\pi=e^{-\left(t_{n+1}-t_{n}\right)/\alpha};\\\nu=e^{-k\left(t_{n+1}-t_{n}\right)/\alpha\left(k-1\right)};\end{cases}\\w_{n+1}=1+\pi w_{n};\\v_{n+1}=1+\nu v_{n};\\s_{n+1}=x_{n+1}+\pi s_{n};\\u_{n+1}=x_{n+1}+\nu u_{n};\\t_{n+1}=t_{n+1}.\end{cases} \]
Then average \[\mu=\frac{ks-\left(k-1\right)u}{kw-\left(k-1\right)v}. \]
Persisted summarizer state thus consists of parameters $\left\{ w,v,s,u,t,k,\alpha\right\}$ . Parameters $k$ and $\alpha$ are set in constructor and thus don't evolve.
Iterative update in-the-past $t_{n+1}<t_{n}$
\[\begin{cases}
\begin{cases}
\pi_{0}=1,\,\nu_{0}=1;\\
\pi=e^{-\left(t_{n}-t_{n+1}\right)/\alpha},\\
\nu=e^{-k\left(t_{n}-t_{n+1}\right)/\alpha\left(k-1\right)};
\end{cases}\\
w_{n+1}=w_{n}+\pi,\\
v_{n+1}=v_{n}+\nu,\\
s_{n+1}=s_{n}+\pi x_{n+1},\\
u_{n+1}=u_{n}+\nu x_{n+1},\\
t_{n+1}=t_{n}.
\end{cases} \]
Combining Canny summarizers
Combining two summarizer states $S_{1},\, S_{2}$ having observed two disjoint sets of original observation superset (for algebraic pig UDF, MapReduce use):
Case $t_{2}\geq t_{1}$ :
\[\begin{cases}
t=t_{2};\\
\pi=e^{-\left(t_{2}-t_{1}\right)/\alpha};\\
\nu=e^{-k\left(t_{2}-t_{1}\right)/\alpha\left(k-1\right)};\\
s=s_{2}+s_{1}\pi;\\
u=u_{2}+u_{1}\nu;\\
w=w_{2}+w_{1}\pi;\\
v=v_{2}+v_{1}\nu.
\end{cases} \]
Merging in positive samples only for binomial cases
Case $t^{\left(1\right)}\geq t^{\left(0\right)}$ :
\[\begin{cases}
t=t^{\left(1\right)};\\
\pi=e^{-\left(t^{\left(1\right)}-t^{\left(0\right)}\right)/\alpha};\\
\nu=e^{-k\left(t^{\left(1\right)}-t^{\left(0\right)}\right)/\alpha\left(k-1\right)};\\
s=s^{\left(1\right)}+s^{\left(0\right)}\pi;\\
u=u^{\left(1\right)}+u^{\left(0\right)};\\
w=w^{\left(0\right)}\pi;\\
v=v^{\left(0\right)}\nu.
\end{cases} \]
Case $t^{\left(1\right)}<t^{\left(0\right)}$ :
\[\begin{cases}
t=t^{\left(0\right)}; & \left(no\, change\right)\\
\pi=e^{-\left(t^{\left(0\right)}-t^{\left(1\right)}\right)/\alpha};\\
\nu=e^{-k\left(t^{\left(0\right)}-t^{\left(1\right)}\right)/\alpha\left(k-1\right)};\\
s=s^{\left(0\right)}+s^{\left(1\right)}\pi;\\
u=u^{\left(0\right)}+u^{\left(1\right)}\nu;\\
w=w^{\left(0\right)}; & \left(no\, change\right)\\
v=v^{\left(0\right)} & (no\, change).
\end{cases} \]
Pecularities of Canny rate summarizer implementation
Assuming $\pi_{0}=1,\,\nu_{0}=1$ , but otherwise
\[\pi=\exp\left(-\frac{\left|t_{n+1}-t_{n}\right|}{\alpha}\right),\]\[\nu=\exp\left(-\frac{k\cdot\left|t_{n+1}-t_{n}\right|}{\alpha\left(k-1\right)}\right),\]
for the case of $t_{n+1}\geq t_{n}$ :
\[\begin{cases}
w_{n+1}=\pi w_{n}+\alpha\left(1-\pi\right);\\
v_{n+1}=\nu v_{n}+\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k};
\end{cases}\]
and for the case of $t_{n+1}<t_{n}$ :
\[\begin{cases}
w_{n+1}=\max\left(w_{n},\alpha\left(1-\pi\right)\right);\\
v_{n+1}=\max\left(v_{n},\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k}\right).
\end{cases} \]
(of course in the latter case if $w_{n}\geq\alpha\left(1-\pi\right)\equiv v_{n}\geq\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k}$ , so we can optimize a little based on that).
The logic of advancing $s_{n+1}$ and $u_{n+1} $ is the same as in Canny average summarizer.
Pecularities of combining Canny rate summarizers
Assuming both summarizers have nonzero history and $\alpha^{\left(1\right)}=\alpha^{\left(2\right)}=\alpha$, and $k^{\left(1\right)}=k^{\left(2\right)}=k$ as a precondition, combining routine looks like
\[\pi=\exp\left(-\frac{\left|t^{\left(2\right)}-t^{(1)}\right|}{\alpha}\right), \]\[\nu=\exp\left(-\frac{k\cdot\left|t^{\left(2\right)}-t_{n}^{\left(1\right)}\right|}{\alpha\left(k-1\right)}\right), \]\[\begin{cases}
\begin{cases}
t=t^{\left(1\right)}\\
s=s^{\left(1\right)}+\pi s^{\left(2\right)}\\
u=u^{\left(1\right)}+\nu u^{\left(2\right)}
\end{cases}, & t^{\left(1\right)}\ge t^{\left(2\right)};\\
\begin{cases}
t=t^{\left(2\right)}\\
s=s^{(2)}+\pi s^{\left(1\right)}\\
u=u^{\left(2\right)}+\nu u^{\left(1\right)}
\end{cases}, & t^{\left(1\right)}<t^{\left(2\right)};\\
w=\max\left(w^{\left(1\right)},w^{\left(2\right)}\right), & \mathrm{all\, cases;}\\
v=\max\left(v^{\left(1\right)},v^{\left(2\right)}\right), & \mathrm{all\, cases.}
\end{cases} \]
In simple words, here we take longest history of two (expressed by denominator terms $w$ and $v$ ), and merge numerators based on which history contained the latest observation. Again, we can assume $w^{\left(1\right)}\ge w^{\left(2\right)}\equiv v^{\left(1\right)}\ge v^{\left(2\right)}$ to save on comparisons a little bit.
Iterative update in-the-past $t_{n+1}<t_{n}$
\[\begin{cases}
\begin{cases}
\pi_{0}=1,\,\nu_{0}=1;\\
\pi=e^{-\left(t_{n}-t_{n+1}\right)/\alpha},\\
\nu=e^{-k\left(t_{n}-t_{n+1}\right)/\alpha\left(k-1\right)};
\end{cases}\\
w_{n+1}=w_{n}+\pi,\\
v_{n+1}=v_{n}+\nu,\\
s_{n+1}=s_{n}+\pi x_{n+1},\\
u_{n+1}=u_{n}+\nu x_{n+1},\\
t_{n+1}=t_{n}.
\end{cases} \]
Combining Canny summarizers
Combining two summarizer states $S_{1},\, S_{2}$ having observed two disjoint sets of original observation superset (for algebraic pig UDF, MapReduce use):
Case $t_{2}\geq t_{1}$ :
\[\begin{cases}
t=t_{2};\\
\pi=e^{-\left(t_{2}-t_{1}\right)/\alpha};\\
\nu=e^{-k\left(t_{2}-t_{1}\right)/\alpha\left(k-1\right)};\\
s=s_{2}+s_{1}\pi;\\
u=u_{2}+u_{1}\nu;\\
w=w_{2}+w_{1}\pi;\\
v=v_{2}+v_{1}\nu.
\end{cases} \]
Merging in positive samples only for binomial cases
Case $t^{\left(1\right)}\geq t^{\left(0\right)}$ :
\[\begin{cases}
t=t^{\left(1\right)};\\
\pi=e^{-\left(t^{\left(1\right)}-t^{\left(0\right)}\right)/\alpha};\\
\nu=e^{-k\left(t^{\left(1\right)}-t^{\left(0\right)}\right)/\alpha\left(k-1\right)};\\
s=s^{\left(1\right)}+s^{\left(0\right)}\pi;\\
u=u^{\left(1\right)}+u^{\left(0\right)};\\
w=w^{\left(0\right)}\pi;\\
v=v^{\left(0\right)}\nu.
\end{cases} \]
Case $t^{\left(1\right)}<t^{\left(0\right)}$ :
\[\begin{cases}
t=t^{\left(0\right)}; & \left(no\, change\right)\\
\pi=e^{-\left(t^{\left(0\right)}-t^{\left(1\right)}\right)/\alpha};\\
\nu=e^{-k\left(t^{\left(0\right)}-t^{\left(1\right)}\right)/\alpha\left(k-1\right)};\\
s=s^{\left(0\right)}+s^{\left(1\right)}\pi;\\
u=u^{\left(0\right)}+u^{\left(1\right)}\nu;\\
w=w^{\left(0\right)}; & \left(no\, change\right)\\
v=v^{\left(0\right)} & (no\, change).
\end{cases} \]
Pecularities of Canny rate summarizer implementation
Assuming $\pi_{0}=1,\,\nu_{0}=1$ , but otherwise
\[\pi=\exp\left(-\frac{\left|t_{n+1}-t_{n}\right|}{\alpha}\right),\]\[\nu=\exp\left(-\frac{k\cdot\left|t_{n+1}-t_{n}\right|}{\alpha\left(k-1\right)}\right),\]
for the case of $t_{n+1}\geq t_{n}$ :
\[\begin{cases}
w_{n+1}=\pi w_{n}+\alpha\left(1-\pi\right);\\
v_{n+1}=\nu v_{n}+\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k};
\end{cases}\]
and for the case of $t_{n+1}<t_{n}$ :
\[\begin{cases}
w_{n+1}=\max\left(w_{n},\alpha\left(1-\pi\right)\right);\\
v_{n+1}=\max\left(v_{n},\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k}\right).
\end{cases} \]
(of course in the latter case if $w_{n}\geq\alpha\left(1-\pi\right)\equiv v_{n}\geq\alpha\frac{\left(k-1\right)\left(1-\nu\right)}{k}$ , so we can optimize a little based on that).
The logic of advancing $s_{n+1}$ and $u_{n+1} $ is the same as in Canny average summarizer.
Pecularities of combining Canny rate summarizers
Assuming both summarizers have nonzero history and $\alpha^{\left(1\right)}=\alpha^{\left(2\right)}=\alpha$, and $k^{\left(1\right)}=k^{\left(2\right)}=k$ as a precondition, combining routine looks like
\[\pi=\exp\left(-\frac{\left|t^{\left(2\right)}-t^{(1)}\right|}{\alpha}\right), \]\[\nu=\exp\left(-\frac{k\cdot\left|t^{\left(2\right)}-t_{n}^{\left(1\right)}\right|}{\alpha\left(k-1\right)}\right), \]\[\begin{cases}
\begin{cases}
t=t^{\left(1\right)}\\
s=s^{\left(1\right)}+\pi s^{\left(2\right)}\\
u=u^{\left(1\right)}+\nu u^{\left(2\right)}
\end{cases}, & t^{\left(1\right)}\ge t^{\left(2\right)};\\
\begin{cases}
t=t^{\left(2\right)}\\
s=s^{(2)}+\pi s^{\left(1\right)}\\
u=u^{\left(2\right)}+\nu u^{\left(1\right)}
\end{cases}, & t^{\left(1\right)}<t^{\left(2\right)};\\
w=\max\left(w^{\left(1\right)},w^{\left(2\right)}\right), & \mathrm{all\, cases;}\\
v=\max\left(v^{\left(1\right)},v^{\left(2\right)}\right), & \mathrm{all\, cases.}
\end{cases} \]
In simple words, here we take longest history of two (expressed by denominator terms $w$ and $v$ ), and merge numerators based on which history contained the latest observation. Again, we can assume $w^{\left(1\right)}\ge w^{\left(2\right)}\equiv v^{\left(1\right)}\ge v^{\left(2\right)}$ to save on comparisons a little bit.
Wednesday, June 1, 2011
On MapReduce application for online exponential rates summarizer.
as a follow-up to Ted Dunning's post exponentially weighted averaging:
Here's the bottom line result from that post:
\[\pi=e^{-\left(t_{n}-t_{n-1}\right)/\alpha}\]\[s_{n}=\pi s_{n-1}+x \]\[w_{n}=\pi w_{n-1}+\left(t-t_{n}\right)\]\[t_{n}= t \]
Some additions are due:
Combiner routine:
In most general case, when both summarizers have non-zero history, and $t_{1}>t_{2}$ ,
\[\pi=e^{-\left(t_{1}-t_{2}\right)/\alpha}, \]\[w=\max\left(w_{1},\pi w_{2}\right), \]\[s=s_{1}+\pi s_{2}.\]
Case $t_{1}<t_{2} $ is symmetrical w.r.t. indices $\left(\cdot\right)_{1},\,\left(\cdot\right)_{2}$ .
This combiner routine however is not consistent with original formula as time spans are not exponentially compressed into time scale. Therefore, unit test for such combiner produces significant errors in various history combinations.
A combine-consistent routine:
A better formulation that works fine with the combiner is as follows:
Case $t_{n+1}>t_{n}$ :
\[\begin{cases}
\Delta t=t_{n+1}-t_{n},\\
\begin{cases}
\pi_{0}=1,\\
\pi_{n+1}=e^{-\Delta t/\alpha};
\end{cases}\\
w_{n+1}=\pi_{n+1}w_{n}+\alpha\cdot(1-\pi_{n+1});\\
s_{n+1}=x_{n+1}+\pi_{n+1}s_{n};\\
t_{n+1}=t_{n+1}.
\end{cases} \]
The term $\alpha\left(1-\pi_{n+1}\right)$ really corresponds to the function average of the exponent function $f\left(x\right)=e^{x}$ multiplied by $\Delta t$ as in
\[\Delta t\cdot\bar{f}\left(x|\left[-\frac{\Delta t}{\alpha},0\right]\right)=\Delta t\cdot\frac{\alpha}{\Delta t}\cdot\int_{-\Delta t/\alpha}^{0}e^{x}dx=\]\[ =\alpha\cdot\left(e^{0}-e^{-\Delta t/\alpha}\right)=\]\[ =\alpha\left(1-\pi\right).\]
Finally, update-in-the-past also looks different for consistency and combining sake:
Case $t_{n+1}<t_{n}$:
\[\begin{cases}
\Delta t=t_{n}-t_{n+1},\\
\begin{cases}
\pi_{0}=1,\\
\pi=e^{-\Delta t/\alpha},
\end{cases}\\
w_{n+1}=\max\left[w_{n},\alpha\cdot\left(1-\pi_{n+1}\right)\right],\\
s_{n+1}=s_{n}+\pi_{n+1}x_{n+1},\\
t_{n+1}=t_{n}. & \left(\mathrm{no\, change}\right)
\end{cases}
\]
Here's the bottom line result from that post:
\[\pi=e^{-\left(t_{n}-t_{n-1}\right)/\alpha}\]\[s_{n}=\pi s_{n-1}+x \]\[w_{n}=\pi w_{n-1}+\left(t-t_{n}\right)\]\[t_{n}= t \]
Some additions are due:
Combiner routine:
In most general case, when both summarizers have non-zero history, and $t_{1}>t_{2}$ ,
\[\pi=e^{-\left(t_{1}-t_{2}\right)/\alpha}, \]\[w=\max\left(w_{1},\pi w_{2}\right), \]\[s=s_{1}+\pi s_{2}.\]
Case $t_{1}<t_{2} $ is symmetrical w.r.t. indices $\left(\cdot\right)_{1},\,\left(\cdot\right)_{2}$ .
This combiner routine however is not consistent with original formula as time spans are not exponentially compressed into time scale. Therefore, unit test for such combiner produces significant errors in various history combinations.
A combine-consistent routine:
A better formulation that works fine with the combiner is as follows:
Case $t_{n+1}>t_{n}$ :
\[\begin{cases}
\Delta t=t_{n+1}-t_{n},\\
\begin{cases}
\pi_{0}=1,\\
\pi_{n+1}=e^{-\Delta t/\alpha};
\end{cases}\\
w_{n+1}=\pi_{n+1}w_{n}+\alpha\cdot(1-\pi_{n+1});\\
s_{n+1}=x_{n+1}+\pi_{n+1}s_{n};\\
t_{n+1}=t_{n+1}.
\end{cases} \]
The term $\alpha\left(1-\pi_{n+1}\right)$ really corresponds to the function average of the exponent function $f\left(x\right)=e^{x}$ multiplied by $\Delta t$ as in
\[\Delta t\cdot\bar{f}\left(x|\left[-\frac{\Delta t}{\alpha},0\right]\right)=\Delta t\cdot\frac{\alpha}{\Delta t}\cdot\int_{-\Delta t/\alpha}^{0}e^{x}dx=\]\[ =\alpha\cdot\left(e^{0}-e^{-\Delta t/\alpha}\right)=\]\[ =\alpha\left(1-\pi\right).\]
Finally, update-in-the-past also looks different for consistency and combining sake:
Case $t_{n+1}<t_{n}$:
\[\begin{cases}
\Delta t=t_{n}-t_{n+1},\\
\begin{cases}
\pi_{0}=1,\\
\pi=e^{-\Delta t/\alpha},
\end{cases}\\
w_{n+1}=\max\left[w_{n},\alpha\cdot\left(1-\pi_{n+1}\right)\right],\\
s_{n+1}=s_{n}+\pi_{n+1}x_{n+1},\\
t_{n+1}=t_{n}. & \left(\mathrm{no\, change}\right)
\end{cases}
\]
Monday, May 30, 2011
Generalized Linear Model + Stochastic Gradient Descent with squared loss

Indeed, what's not to like. It is fast. It's simple. It's intuitive.
The principle is extremely simple. If you have a statistical model based on bunch of parameters $${\beta}_0$$, $${\beta}_1$$ ... and you have a loss function $$\mathcal{L}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)$$, and you want to minimize loss w.r.t. $$\boldsymbol{\beta}$$ parameters of the model, then you go thru your input and at each step you try to adjust parameters using simple iterative notion of
\[\boldsymbol{\beta}_{i+1}=\boldsymbol{\beta}_{i}-\gamma\cdot\nabla_{\beta}\mathcal{L},\]
where $$\gamma$$ is called learning rate and can be found adaptively based on results of crossvalidation of the trained model. (Here, bold symbols denote vectors).
So, can we generalize formulas when applied to Generalized Linear Models?
Indeed, GLM formulation is
\[G\left(y\right)=\eta\left(\boldsymbol{x}\right),\]
where
\[\eta\left(\boldsymbol{x}\right)=\boldsymbol{\beta}^{\top}\boldsymbol{x}.\]
We take the perhaps the simplest, squared loss approach, where loss funciton is
\[\mathcal{L}=\sum_{i}\left(y_{i}-\hat{y}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)\right)^{2}+\lambda\rho\left(\boldsymbol{\beta}\right),\]
where $$\lambda$$ is regularization rate, and $$\rho\left(\cdot\right)$$ is usually choosen based on prior distribution for regression parameters (which commonly is L1, L2 or t-prior).
Loss function gradient over $$\boldsymbol{\beta}$$ in case of GLM+SGD (individual SGD step)
\[\nabla_{\beta}\mathcal{L}_{i}=\nabla_{\beta}\left[\left(y_{i}-\hat{y}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)\right)^{2}+\lambda\rho\left(\boldsymbol{\beta}\right)\right]=\]
\[=2\left(y_{i}-\hat{y}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)\right)\cdot\nabla_{\beta}\left(y_{i}-\hat{y}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)\right)+\lambda\nabla_{\beta}\rho\left(\boldsymbol{\beta}\right)=\]
\[=-2r_{i}\frac{dG^{-1}}{d\eta}\boldsymbol{x}_{i}+\lambda\nabla_{\beta}\rho\left(\boldsymbol{\beta}\right).\]
Here, $$r_{i}=y_{i}-\hat{y}\left(\boldsymbol{x}_{i}|\boldsymbol{\beta}\right)$$ is a residual at the i -th step of SGD. Which leads us to a commonly used form of SGD with squared loss
\[\boldsymbol{\beta}_{i+1}=\boldsymbol{\beta}_{i}-\gamma\cdot\nabla_{\beta}\mathcal{L},\]
or, removing some constant multipliers for convenience,
\[\boldsymbol{\beta}_{i+1}=\boldsymbol{\beta}_{i}+\gamma\cdot\left(r_{i+1}\frac{dG^{-1}}{d\eta}\boldsymbol{x}_{i+1}-\lambda\nabla_{\beta}\rho\left(\boldsymbol{\beta}\right)\right).\]
Since $$G^{-1}$$ is always a monotonically increasing function, many implementations replace its derivative term $$\frac{dG^{-1}}{d\eta}$$ with 1 (in particular, logistic regression where calculating derivative requires an exponent computation).
L2 regularization would look like
\[\rho\left(\boldsymbol{\beta}\right)=\left\Vert \boldsymbol{\beta}\right\Vert {}_{2}^{2}\Rightarrow\nabla\rho\left(\boldsymbol{\beta}\right)=\boldsymbol{\beta}.\]
L1 (less common) regularization would look like
\[\rho\left(\boldsymbol{\beta}\right)=\left|\left\Vert \boldsymbol{\beta}\right\Vert _{1}\right|\Rightarrow\nabla\rho\left(\boldsymbol{\beta}\right)=\left(\begin{matrix}1\\\vdots\\1\end{matrix}\right).\]
So it's clear that GLM object model now can be considered as consisting of general SGD core algorithm and two strategy patterns: link function and regularization.
Link function strategy needs to provide inverse link and inverse link prime computations.
Regularization abstraction needs to provide partial derivative computation $$\frac{\partial\rho}{\partial\beta_{i}}$$ given (set) of regression coefficients (and perhaps an input $$x$$, too, although neither L1 nor L2 really care of the $$x$$).
Identity link function with no regularization would mean Linear regression, Identity link function + L1 gives us LASSO regression, Identity link function + L2 gives us Ridge regression, Logit link function produces logistic regression, and, finally, exponential link function produces Poisson regression, or a.k.a log-linear models (If i am not mistaken).
Finding hyperparameters $$\gamma$$ and $$\lambda$$ is a separate rather interesting search optimization task.
Tuesday, April 26, 2011
Supercomputing Is a Religion But Clouds Are Mundane

By supercomputers I ofcourse only mean hardware-based NUMA architectures; commodity hardware based simulations with LAN links (such as Beowulf) IMO are really too slow to be seriously considered NUMA type supercomputers.
 Clouds are, on the other hand, are as mundane as a toothbrush. Clouds are as versatile as a minivan. And, you can scale them at a fraction of a cost to have as many cpus as supercomputers do. In that sense, paraphrasing the old saying "today's supercomputer is tomorrow's computer", today's supercomputer is today's cloud. The only problem is there's virtually no shared memory space for those CPUs, and so it takes forever to move data from one CPU to another (compared to NUMA). So you can only harness the power of those cpus if you parallelize work in independent splits big enough so that the cloud could be loaded for long enough before the need for sharing split computations arises again. But wouldn't it be cool if that toothbrush could solve as big problems as its supercomputer counterpart with the same amount of cores might? Wouldn't it be nice for a moment to feel a Demigod's power rushing in one's veins while doing that annoying weeding in your backyard?
Clouds are, on the other hand, are as mundane as a toothbrush. Clouds are as versatile as a minivan. And, you can scale them at a fraction of a cost to have as many cpus as supercomputers do. In that sense, paraphrasing the old saying "today's supercomputer is tomorrow's computer", today's supercomputer is today's cloud. The only problem is there's virtually no shared memory space for those CPUs, and so it takes forever to move data from one CPU to another (compared to NUMA). So you can only harness the power of those cpus if you parallelize work in independent splits big enough so that the cloud could be loaded for long enough before the need for sharing split computations arises again. But wouldn't it be cool if that toothbrush could solve as big problems as its supercomputer counterpart with the same amount of cores might? Wouldn't it be nice for a moment to feel a Demigod's power rushing in one's veins while doing that annoying weeding in your backyard?So, what can we do about highly interconnected problems that rely a lot on shared memory to parallelize a solution?
Fortunately, many interconnected problems in their traditional solutions are connected much more than necessary just because software abstractions such as MPI make shared memory access look cheap and iterative approach is used more than it needs be. Or at least less iterative approach exists. It's just sometimes you need a Demigod's wisdom to see it. But as they say it in the east, the need is the forefather of all inventions.

Thursday, April 21, 2011
Follow-up for the "Mean Summarizer..." post

In practice, in MapReduce world, such as Pig UDF functions (which I btw already put in place), when we run over observation data, we often encounter 2 types of problems:
1-- Unordered observations, i.e. cases such as $$t_{n+1}<t_{n}$$.
2-- Parallel processing of disjoint subsets of common superset of observations and combining into one ("combiner"-hadoop, "Algebraic UDF"-pig).
Hence, we need to add those specific cases to our formulas.
1. Updating state with events in the past.
Updated formula will look like:
Case $$t_{n+1}\geq t_{n} $$:
\[\begin{cases}\begin{cases}\pi_{0}=1,\\\pi_{n+1}=e^{-\left(t_{n+1}-t_{n}\right)/\alpha};\end{cases}\\w_{n+1}=1+\pi_{n+1}w_{n};\\s_{n+1}=x_{n+1}+\pi_{n+1}s_{n};\\t_{n+1}=t_{n+1}.\end{cases}\]
Case $$t_{n+1}<t_{n}$$ (updating in-the-past):
\[\begin{cases}\begin{cases}\pi_{0}=1,\\\pi=e^{-\left(t_{n}-t_{n+1}\right)/\alpha},\end{cases}\\w_{n+1}=w_{n}+\pi_{n+1},\\s_{n+1}=s_{n}+\pi_{n+1}x_{n+1},\\t_{n+1}=t_{n}.\end{cases}\]
2. Combining two summarizers having observed two disjoint sets as subsets of original observation set.
Combining two summarizer states $$S_{1},\, S_{2}$$ having observed two disjoint sets of original observation superset:
Case $$t_{2}\geq t_{1}$$:
\[\begin{cases}t=t_{2};\\s=s_{2}+s_{1}e^{-\left(t_{2}-t_{1}\right)/\alpha};\\w=w_{2}+w_{1}e^{-\left(t_{2}-t_{1}\right)/\alpha}.\end{cases}\]
Case $$t_{2}<t_{1}$$ is symmetrical w.r.t. indices $$\left(\cdot\right)_{1},\left(\cdot\right)_{2}$$. Also, the prerequisite for combining two summarizers is $$\alpha_{1}=\alpha_{2}=\alpha$$ (history decay is the same).
But enough of midnight oil burning.
Tuesday, April 12, 2011
Online mean summarizer for binomial distribution with irregular sampling and arbitrary bias
Suppose we have a task to provide biased estimate on probability sampled by $$\left(x_{1},...x_{n}\right),\, x_{i}\in\left\{ 0,1\right\}$$. Traditional solution for a biased estimate is mean of a conjugate prior. In this case it would be mean of the beta-distribution \[P_{n}=\mathbb{E}\left(\mu_{B}\right)=\frac{\alpha}{\alpha+\beta},\] where $$\alpha$$ equals to number of positive outcomes +1 and $$\beta$$ is taken as number of negative outcomes +1.
The obvious intention of biased estimate is to converge on certain bias $$P_{0}$$ in absence of a good sample data: \[P_{0}=\lim_{n\rightarrow0}P_{n}.\]
In case of standard beta-distribution $$P_{0}={1\over{2}}$$, which of course is not terribly useful in practice. In practice we may have much better 'guesses' for our initial estimate. So in order to allow arbitrary parameterization for $$P_{0}$$, let's denote $$\alpha=n_{+}+b_{+}$$ and $$\beta=n_{-}+b_{-}$$, $$n_{-}$$ being the number of negative observations and $$n_{+}$$ being the number of positive observations. Values $$b_{+}$$ and $$b_{-}$$ thus express our initial bias towards positive and negative outcome of final estimate, respectively.
Then our online summarizer could be presented as \[P_{n}=\frac{b_{+}+\sum_{i}^{n}x_{i}}{n+b_{-}+b_{+}}\] and it's not hard to see that we can come up with heuristics allowing arbitrary bias \[P_{0}=\lim_{n\rightarrow0}P_{n}=\frac{b_{+}}{b_{+}+b_{-}}\] while keeping $$b_{+}+b_{-}=2$$ per standard beta-distribution.
That's the biased summarizer I have been using until I saw this post.
If our sampling $$\left(x_{1},...x_{n}\right),\, x_{i}\in\left\{ 0,1\right\}$$ is also taken at times $$t_{1},...t_{n}$$ then we can factor in exponential phase-out for more distant history while taking more recent history into account. Also, instead of converging onto our bias $$P_{0}$$ when we just have a lack of history, we can also converge on it if we have lack of recent history: \[\lim_{n\rightarrow0}P=\frac{b_{+}}{b_{+}+b_{-}}=P_{0}\] and \[\lim_{\left(t_{n}-t_{n-1}\right)\rightarrow+\infty}P=\frac{b_{+}}{b_{+}+b_{-}}=P_{0}.\]
Cool. How do we exactly do that in a convenient way?
 We can modify result from Ted Dunning's post I referenced above in the following way:\[P=\frac{b_{+}+\sum_{i=1}^{n}x_{i}e^{-\left(t-t_{i}\right)/\alpha}}{b_{-}+b_{+}+\sum_{i=1}^{n}e^{-\left(t-t_{i}\right)/\alpha}}.\]
We can modify result from Ted Dunning's post I referenced above in the following way:\[P=\frac{b_{+}+\sum_{i=1}^{n}x_{i}e^{-\left(t-t_{i}\right)/\alpha}}{b_{-}+b_{+}+\sum_{i=1}^{n}e^{-\left(t-t_{i}\right)/\alpha}}.\]
It's not hard to see that our goals described by limits above would hold with this solution.
The iterative solution for that would be \[\pi_{n+1}=e^{-\left(t_{n+1}-t_{n}\right)/\alpha},\] \[w_{n+1}=1+\pi_{n+1}w_{n},\] \[s_{n+1}=x_{n+1}+\pi_{n+1}s_{n},\] \[P_{n+1}=\frac{b_{+}+s_{n+1}}{b_{+}+b_{-}+w_{n+1}}.\]
We also have to go by selecting our $$b_{+}$$ and $$b_{-}$$ values more carefully, since value of samples is exponentially decreasing. So it stands to reason we want to decrease effect of our bias based on the amount of history, exponentially weighted, as well. Suppose we have a metric $$\varepsilon$$ that denotes amount of non-significant history for the purposes of biasing. Then we want to modify condition $$b_{+}+b_{-}=2$$ based on non-weighted history by using exponential function average \[b_{+}+b_{-}=2\cdot\frac{\int_{0}^{-\ln\varepsilon}e^{-t}dt}{-\ln\varepsilon}=2\cdot\frac{\varepsilon-1}{\ln\varepsilon}.\] This gives us solution for bias parameters as \[\begin{cases}b_{+}=2P_{0}\frac{\varepsilon-1}{\ln\varepsilon};\\b_{-}=2\left(1-P_{0}\right)\frac{\varepsilon-1}{\ln\varepsilon}.\end{cases}\]
Also, having to specify $$\alpha$$ is weird. Most people like to look at it as span of useful history $$\Delta{t}$$ and margin $$m$$, in exponential scale, when the rest of history is not deemed very useful. Good default value for $$m$$ is perhaps 0.01 (1%). Then we can compute $$\alpha$$ as \[\alpha=\frac{-\Delta t}{\ln m}.\]
So, building the summarizer, we have iterative state represented by $$\left\{ w_{n},s_{n},t_{n}\right\}$$ and non-default constructor that accepts $$\Delta{t},m,P_{0}$$ and $$\varepsilon$$ and transforms them into parameters of the summarizer : $$b_{-},b_{+},\alpha$$ per above.
The summarizer needs to implement 2 methods: $$\mathrm{pnow}(t)$$ and $$\mathrm{update}(t_{n},x_{n})$$. The implementation of the update() method pretty much follows from all the above. The implementation of pnow() just needs to compute probability for current moment (we don't have an observation and may be more biased if we did not see recent observations). Method pnow() just needs to do the same estimate as update() assuming $$t_{n}$$ as 'now' and $$s_{n+1}=\pi_{n+1}s_{n}$$ and $$w_{n+1}=\pi_{n+1}w_{n}$$ and without actually updating the state $$\left\{ w_{n},s_{n},t_{n}\right\}$$.
 Did I say that some version of constructor could assume default values for $$\varepsilon$$ and $$m$$? I use $$\varepsilon=0.5$$ and $$m=0.01$$ as default. So one of good versions of constructor is the one that accepts bias aka 'null hypothesis' $$P_{0}$$, and the span of useful history $$\Delta t$$ to phase out on.
Did I say that some version of constructor could assume default values for $$\varepsilon$$ and $$m$$? I use $$\varepsilon=0.5$$ and $$m=0.01$$ as default. So one of good versions of constructor is the one that accepts bias aka 'null hypothesis' $$P_{0}$$, and the span of useful history $$\Delta t$$ to phase out on.
So a bit of coding, and we start converging on a pretty picture in no time.
(And yes, I do take all my pictures myself as well as doing the coding part.)
The obvious intention of biased estimate is to converge on certain bias $$P_{0}$$ in absence of a good sample data: \[P_{0}=\lim_{n\rightarrow0}P_{n}.\]
In case of standard beta-distribution $$P_{0}={1\over{2}}$$, which of course is not terribly useful in practice. In practice we may have much better 'guesses' for our initial estimate. So in order to allow arbitrary parameterization for $$P_{0}$$, let's denote $$\alpha=n_{+}+b_{+}$$ and $$\beta=n_{-}+b_{-}$$, $$n_{-}$$ being the number of negative observations and $$n_{+}$$ being the number of positive observations. Values $$b_{+}$$ and $$b_{-}$$ thus express our initial bias towards positive and negative outcome of final estimate, respectively.
Then our online summarizer could be presented as \[P_{n}=\frac{b_{+}+\sum_{i}^{n}x_{i}}{n+b_{-}+b_{+}}\] and it's not hard to see that we can come up with heuristics allowing arbitrary bias \[P_{0}=\lim_{n\rightarrow0}P_{n}=\frac{b_{+}}{b_{+}+b_{-}}\] while keeping $$b_{+}+b_{-}=2$$ per standard beta-distribution.
That's the biased summarizer I have been using until I saw this post.
If our sampling $$\left(x_{1},...x_{n}\right),\, x_{i}\in\left\{ 0,1\right\}$$ is also taken at times $$t_{1},...t_{n}$$ then we can factor in exponential phase-out for more distant history while taking more recent history into account. Also, instead of converging onto our bias $$P_{0}$$ when we just have a lack of history, we can also converge on it if we have lack of recent history: \[\lim_{n\rightarrow0}P=\frac{b_{+}}{b_{+}+b_{-}}=P_{0}\] and \[\lim_{\left(t_{n}-t_{n-1}\right)\rightarrow+\infty}P=\frac{b_{+}}{b_{+}+b_{-}}=P_{0}.\]
Cool. How do we exactly do that in a convenient way?
We can modify result from Ted Dunning's post I referenced above in the following way:\[P=\frac{b_{+}+\sum_{i=1}^{n}x_{i}e^{-\left(t-t_{i}\right)/\alpha}}{b_{-}+b_{+}+\sum_{i=1}^{n}e^{-\left(t-t_{i}\right)/\alpha}}.\]It's not hard to see that our goals described by limits above would hold with this solution.
The iterative solution for that would be \[\pi_{n+1}=e^{-\left(t_{n+1}-t_{n}\right)/\alpha},\] \[w_{n+1}=1+\pi_{n+1}w_{n},\] \[s_{n+1}=x_{n+1}+\pi_{n+1}s_{n},\] \[P_{n+1}=\frac{b_{+}+s_{n+1}}{b_{+}+b_{-}+w_{n+1}}.\]
We also have to go by selecting our $$b_{+}$$ and $$b_{-}$$ values more carefully, since value of samples is exponentially decreasing. So it stands to reason we want to decrease effect of our bias based on the amount of history, exponentially weighted, as well. Suppose we have a metric $$\varepsilon$$ that denotes amount of non-significant history for the purposes of biasing. Then we want to modify condition $$b_{+}+b_{-}=2$$ based on non-weighted history by using exponential function average \[b_{+}+b_{-}=2\cdot\frac{\int_{0}^{-\ln\varepsilon}e^{-t}dt}{-\ln\varepsilon}=2\cdot\frac{\varepsilon-1}{\ln\varepsilon}.\] This gives us solution for bias parameters as \[\begin{cases}b_{+}=2P_{0}\frac{\varepsilon-1}{\ln\varepsilon};\\b_{-}=2\left(1-P_{0}\right)\frac{\varepsilon-1}{\ln\varepsilon}.\end{cases}\]
Also, having to specify $$\alpha$$ is weird. Most people like to look at it as span of useful history $$\Delta{t}$$ and margin $$m$$, in exponential scale, when the rest of history is not deemed very useful. Good default value for $$m$$ is perhaps 0.01 (1%). Then we can compute $$\alpha$$ as \[\alpha=\frac{-\Delta t}{\ln m}.\]
So, building the summarizer, we have iterative state represented by $$\left\{ w_{n},s_{n},t_{n}\right\}$$ and non-default constructor that accepts $$\Delta{t},m,P_{0}$$ and $$\varepsilon$$ and transforms them into parameters of the summarizer : $$b_{-},b_{+},\alpha$$ per above.
The summarizer needs to implement 2 methods: $$\mathrm{pnow}(t)$$ and $$\mathrm{update}(t_{n},x_{n})$$. The implementation of the update() method pretty much follows from all the above. The implementation of pnow() just needs to compute probability for current moment (we don't have an observation and may be more biased if we did not see recent observations). Method pnow() just needs to do the same estimate as update() assuming $$t_{n}$$ as 'now' and $$s_{n+1}=\pi_{n+1}s_{n}$$ and $$w_{n+1}=\pi_{n+1}w_{n}$$ and without actually updating the state $$\left\{ w_{n},s_{n},t_{n}\right\}$$.
So a bit of coding, and we start converging on a pretty picture in no time.
(And yes, I do take all my pictures myself as well as doing the coding part.)
Monday, April 4, 2011
Git, Github and committing to ASF svn
There has been a discussion around ASF what the best practices of git/github/ASF svn might be. I am ready to offer my own variation.
It's been some time since ASF (Apache Software Foundation) enabled git mirrors of its SVN repository. Github has been mirroring those for some time.
E.g. Mahout project has apache git url git://git.apache.org/mahout.git which in turn is mirrored in Github as git@github.apache.org:apache/mahout.git. Being a Mahout committer myself, I will use it further as an example.
Consequently, it is possible to use Github's collaboration framework to collaborate on individual project issues, accept additions from contributors, merging/branching even more etc. In other words, enable individual jira issue to have its own commit history without really exposing this history to the final project. Another benefit is to have all the power of 3- or whatever-way rebases and merges git provides instead of having a single patch which often gets out of sync with the trunk.
And of course, ability of git to be a 'distributed' system. Your own copy is always your own play yard as well with full power of ... and so on and so forth.
So.. how do we sync apache svn with git branch?
We use git's paradigm of upstream branch, of course, with svn trunk being an upstream. Sort of.
Of course, svn doesn't support upstream tracking, not directly anyway.
First, let's clone the project and set up svn 'upstream' :
I used to run 'git svn clone...' here, but as this wonderful document points out, you can save a lot of time by cloning apache git instead of svn.
Also don't forget to install the authors file from http://git.apache.org/authors.txt by running
assuming that's the path where you put it. Otherwise, your local git commit metadata will be different from that of created in git.apache.org and as a result, that commit's hash will also be different. "svn rebase" would reconcile it though, it seems.
We could also use 'fork' capability in github to create our repository clone, i think. It would be yet even more faster. Now that i have already a cloned repository, I cannot clone yet one more since Github doesn't seem to allow to have more than 1 fork of another repository. Oh well...
So, we are now in our 'holy cow', trunk branch. We will not work here but only use it for commits. It is also recommended to configure git-svn with svn 'authors' file per that info in apache wiki above, for committers.
Now, say we want to create a branch in Github repository, git@github.com:dlyubimov/mahout-commits which we pre-created using Github tools.
1-- creates remote corresponding to github repository, in local repository.
2-- make sure we are on local branch 'trunk'
3-- creates local branch MAHOUT-622 based on current (trunk) branch and switches to it
4-- pushes (in this case, also creates) current local MAHOUT-622 branch to github/MAHOUT-622 and also sets up upstream tracking for it. This would take significantly less time if we used Github's 'fork' as mentioned above.
Now we can create some commit history for github/MAHOUT-622 using Github collaboration (pull requests, etc.) So we are reasonably satisfied with the branch and want to commit it to trunk. Here is what we do :
1-- switch to MAHOUT-622
2-- fast-forward to latest changes in github remote branch
3-- switch to trunk
4-- pull latest changes from svn (just in case)
5-- merge all changes from MAHOUT-622 onto trunk tree without committing. At this point, if any merge conflicts are reported, resolve them (perhaps using 'git mergetool') if necessary;
6-- format future single svn commit for MAHOUT-622 issue as a single commit
7-- optionally check the patch of what we just changed before pushing it to svn. Also, since we just merged it here, i.e. potentially added some more changes to the original patch, do all the due diligence here: check for build, tests passing, etc. whatever else committers do.
8-- push commit to svn. European users are recommended to use --no-rebase option while doing this and then explicitly rebase several seconds later.
Alternatively, in step 5 we can merge directly from remote github branch as:
Note that in this case, instead of pulling, we need to run 'git fetch github' in order to update remote commit tree in the local reference repo.
If we wanted to publish a patch into JIRA so that others could review it, we could do it by running 'git diff trunk MAHOUT-622' or just 'git diff trunk' if we are on MAHOUT-622 already.
Yet another use case is when we want to merge upstream svn changes into the issue we are working on :
2-- pull latest from 'upstream' ASF svn
3-- switch to MAHOUT-622
4-- pull latest remote collaborations to local MAHOUT-622
5-- merge trunk onto issue branch. If conflicts are reported, resolve them (perhaps using 'git mergetool');
6-- push updates to the remote github issue branch. Since we set up the issue branch to track github's branch, we can just use the default form of 'git push'.

It's been some time since ASF (Apache Software Foundation) enabled git mirrors of its SVN repository. Github has been mirroring those for some time.
E.g. Mahout project has apache git url git://git.apache.org/mahout.git which in turn is mirrored in Github as git@github.apache.org:apache/mahout.git. Being a Mahout committer myself, I will use it further as an example.
Consequently, it is possible to use Github's collaboration framework to collaborate on individual project issues, accept additions from contributors, merging/branching even more etc. In other words, enable individual jira issue to have its own commit history without really exposing this history to the final project. Another benefit is to have all the power of 3- or whatever-way rebases and merges git provides instead of having a single patch which often gets out of sync with the trunk.
And of course, ability of git to be a 'distributed' system. Your own copy is always your own play yard as well with full power of ... and so on and so forth.
So.. how do we sync apache svn with git branch?
We use git's paradigm of upstream branch, of course, with svn trunk being an upstream. Sort of.
Of course, svn doesn't support upstream tracking, not directly anyway.
First, let's clone the project and set up svn 'upstream' :
git clone git://git.apache.org/mahout.git mahout-svn git svn init --prefix=origin/ --tags=tags --trunk=trunk --branches=branches https://svn.apache.org/repos/asf/mahout git svn rebase
I used to run 'git svn clone...' here, but as this wonderful document points out, you can save a lot of time by cloning apache git instead of svn.
Also don't forget to install the authors file from http://git.apache.org/authors.txt by running
git config svn.authorsfile ".git/authors.txt"
assuming that's the path where you put it. Otherwise, your local git commit metadata will be different from that of created in git.apache.org and as a result, that commit's hash will also be different. "svn rebase" would reconcile it though, it seems.
We could also use 'fork' capability in github to create our repository clone, i think. It would be yet even more faster. Now that i have already a cloned repository, I cannot clone yet one more since Github doesn't seem to allow to have more than 1 fork of another repository. Oh well...
So, we are now in our 'holy cow', trunk branch. We will not work here but only use it for commits. It is also recommended to configure git-svn with svn 'authors' file per that info in apache wiki above, for committers.
Now, say we want to create a branch in Github repository, git@github.com:dlyubimov/mahout-commits which we pre-created using Github tools.
git remote add github git@github.com:dlyubimov/mahout-commits git checkout trunk git checkout -b MAHOUT-622 git push -u github
1-- creates remote corresponding to github repository, in local repository.
2-- make sure we are on local branch 'trunk'
3-- creates local branch MAHOUT-622 based on current (trunk) branch and switches to it
4-- pushes (in this case, also creates) current local MAHOUT-622 branch to github/MAHOUT-622 and also sets up upstream tracking for it. This would take significantly less time if we used Github's 'fork' as mentioned above.
Now we can create some commit history for github/MAHOUT-622 using Github collaboration (pull requests, etc.) So we are reasonably satisfied with the branch and want to commit it to trunk. Here is what we do :
git checkout MAHOUT-622 git pull git checkout trunk git svn rebase git merge MAHOUT-622 --squash git commit -m "MAHOUT-622: cleaning up dependencies" git log -p -1 git svn dcommit
1-- switch to MAHOUT-622
2-- fast-forward to latest changes in github remote branch
3-- switch to trunk
4-- pull latest changes from svn (just in case)
5-- merge all changes from MAHOUT-622 onto trunk tree without committing. At this point, if any merge conflicts are reported, resolve them (perhaps using 'git mergetool') if necessary;
6-- format future single svn commit for MAHOUT-622 issue as a single commit
7-- optionally check the patch of what we just changed before pushing it to svn. Also, since we just merged it here, i.e. potentially added some more changes to the original patch, do all the due diligence here: check for build, tests passing, etc. whatever else committers do.
8-- push commit to svn. European users are recommended to use --no-rebase option while doing this and then explicitly rebase several seconds later.
Alternatively, in step 5 we can merge directly from remote github branch as:
git checkout trunk git svn rebase git fetch github git merge github/MAHOUT-622 --squash git commit -m "MAHOUT-622: cleaning up dependencies" git log -p -1 git svn dcommit
Note that in this case, instead of pulling, we need to run 'git fetch github' in order to update remote commit tree in the local reference repo.
If we wanted to publish a patch into JIRA so that others could review it, we could do it by running 'git diff trunk MAHOUT-622' or just 'git diff trunk' if we are on MAHOUT-622 already.
Yet another use case is when we want to merge upstream svn changes into the issue we are working on :
git checkout trunk git svn rebase git checkout MAHOUT-622 git pull git merge trunk git push1-- switch to the 'holy cow'
2-- pull latest from 'upstream' ASF svn
3-- switch to MAHOUT-622
4-- pull latest remote collaborations to local MAHOUT-622
5-- merge trunk onto issue branch. If conflicts are reported, resolve them (perhaps using 'git mergetool');
6-- push updates to the remote github issue branch. Since we set up the issue branch to track github's branch, we can just use the default form of 'git push'.
Sunday, March 27, 2011
Streaming QR decomposition for MapReduce part III: Collecting Q by Induction
In Part II, as a part of bottom-up divide-and-conquer parallelization strategy, one problem emerged that we need to solve at every node of bottom-up tree:
Let's simplify the problem for a moment (as it turns out, vertical blocking of Q is trivial as they are always produced by application of column-wise Givens operations which we can 'replay' on any Q block).
Also let's decompose standard Givens QR operation in to two:
1) producing Givens transformation sequence on some input $m\times n$, $m>n$ A as $$\left(\mathbf{G}_{1},\mathbf{G}_{2}...\mathbf{G}_{k}\right)=\mathrm{givens\_qr}\left(\mathbf{A}\right)$$. I will denote product of all Givens operations obtained this way as $$\prod_{i}\mathbf{G}_{i}\equiv\prod\mathrm{givens\_qr}\left(\mathbf{A}\right)$$.
2) Applying product of Givens operations on input produces already familiar result
\[\left(\prod_{i}\mathbf{G}_{i}\right)^{\top}\mathbf{A}=\left(\begin{matrix}\mathbf{R}\\\mathbf{Z}\end{matrix}\right)\]
from which it follows that thin QR's R can be written as
\[\mathbf{R}=\left[\left(\prod_{i}\mathbf{G}_{i}\right)^{\top}\mathbf{A}\right]\left(1:n,:\right)=\left[\left(\prod\mathrm{givens\_qr}\left(\mathbf{A}\right)\right)^{\top}\mathbf{A}\right]\left(1:n,:\right)\]
using Golub/Van Loan's block notation.
(Golub/Van Loan's block notation in form of A(a1:a2, b1:b2) means "crop of a matrix A, rows a1 to a2 and columns b1 to b2". For half- and full-open intervals the bounds are just omitted).
'Thick' Q is produced by $$\mathbf{I}\left(\prod_{i}\mathbf{G}_{i}\right)$$ and hence 'thin Q' is
\[\mathbf{Q}=\left[\mathbf{I}\left(\prod_{i}\mathbf{G}_{i}\right)\right]\left(:,1:n\right)=\left[\mathbf{I}\left(\prod_{i}\mathrm{givens\_qr}\left(\mathbf{A}\right)\right)\right]\left(:,1:n\right),\mathbf{\,\, I}\in\mathbb{R}^{m\times m}.\]
Now that we laid out all notations, let's get to the gist. As I mentioned before, I continue building algorithm by induction. Let's consider case (2) for $$z=2$$. Then it can be demonstrated that the following is the solution as it is equivalent to full Givens QR with a rearranged but legitimate order of Givens operations:
Finally, a word about how to transform solution for (2) into a solution for (1).
We can rewrite indexes in (1) as
And then regroup that into k independent tasks solving
which can be solved via solution for (2).
That may also be one of parallelization strategies.
That wasn't so hard, was it? It's possible I am performing a subpar re-tracing of some existing research or method here. But I don't think there's much work about how to fit QR onto parallel batch machinery.
I hope that some horizons perhaps became a little clearer.

$$\left(\begin{matrix}\left(\begin{matrix}\mathbf{Q}_{1}\\\mathbf{Q}_{2}\\\vdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{1}\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\vdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{2}\\\vdots\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\vdots\\\mathbf{Q}_{z}\end{matrix}\right)\mathbf{R}_{n}\end{matrix}\right)=\left(\begin{matrix}\mathbf{\hat{Q}}\\\mathbf{\hat{Q}}\\\vdots\\\mathbf{\hat{Q}}\end{matrix}\right)\mathbf{\hat{R}}$$ (1)
Let's simplify the problem for a moment (as it turns out, vertical blocking of Q is trivial as they are always produced by application of column-wise Givens operations which we can 'replay' on any Q block).
$$\left(\begin{matrix}\mathbf{Q}_{1}\mathbf{R}_{1}\\\mathbf{Q}_{2}\mathbf{R}_{2}\\\cdots\\\mathbf{Q}_{z}\mathbf{R}_{z}\end{matrix}\right)\Rightarrow\left(\begin{matrix}\mathbf{\hat{Q}}_{1}\\\mathbf{\hat{Q}}_{2}\\\cdots\\\mathbf{\hat{Q}}_{z}\end{matrix}\right)\hat{\mathbf{R}}$$ (2)
Also let's decompose standard Givens QR operation in to two:
1) producing Givens transformation sequence on some input $m\times n$, $m>n$ A as $$\left(\mathbf{G}_{1},\mathbf{G}_{2}...\mathbf{G}_{k}\right)=\mathrm{givens\_qr}\left(\mathbf{A}\right)$$. I will denote product of all Givens operations obtained this way as $$\prod_{i}\mathbf{G}_{i}\equiv\prod\mathrm{givens\_qr}\left(\mathbf{A}\right)$$.
2) Applying product of Givens operations on input produces already familiar result
\[\left(\prod_{i}\mathbf{G}_{i}\right)^{\top}\mathbf{A}=\left(\begin{matrix}\mathbf{R}\\\mathbf{Z}\end{matrix}\right)\]
from which it follows that thin QR's R can be written as
\[\mathbf{R}=\left[\left(\prod_{i}\mathbf{G}_{i}\right)^{\top}\mathbf{A}\right]\left(1:n,:\right)=\left[\left(\prod\mathrm{givens\_qr}\left(\mathbf{A}\right)\right)^{\top}\mathbf{A}\right]\left(1:n,:\right)\]
using Golub/Van Loan's block notation.
(Golub/Van Loan's block notation in form of A(a1:a2, b1:b2) means "crop of a matrix A, rows a1 to a2 and columns b1 to b2". For half- and full-open intervals the bounds are just omitted).
'Thick' Q is produced by $$\mathbf{I}\left(\prod_{i}\mathbf{G}_{i}\right)$$ and hence 'thin Q' is
\[\mathbf{Q}=\left[\mathbf{I}\left(\prod_{i}\mathbf{G}_{i}\right)\right]\left(:,1:n\right)=\left[\mathbf{I}\left(\prod_{i}\mathrm{givens\_qr}\left(\mathbf{A}\right)\right)\right]\left(:,1:n\right),\mathbf{\,\, I}\in\mathbb{R}^{m\times m}.\]
Now that we laid out all notations, let's get to the gist. As I mentioned before, I continue building algorithm by induction. Let's consider case (2) for $$z=2$$. Then it can be demonstrated that the following is the solution as it is equivalent to full Givens QR with a rearranged but legitimate order of Givens operations:
$$\mathbf{\hat{R}}=\left\{\left[\prod\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right]^{\top}\cdot\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right\} \left(1:n,:\right)$$,
$$\mathbf{\hat{Q}=}\left[\left(\begin{matrix}\mathbf{Q}_{1} & \mathbf{Z}\\\mathbf{Z} & \mathbf{Q}_{2}\end{matrix}\right)\cdot\prod_{i}\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right]\left(:,1:n\right)$$.
Let's denote function of 2-block computation of $$\mathbf{\hat{R}}$$ as
$$\mathrm{rhat}\left(\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left\{\left[\prod\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{i}\\\mathbf{R}_{j}\end{matrix}\right)\right]^{\top}\cdot\left(\begin{matrix}\mathbf{R}_{i}\\\mathbf{R}_{j}\end{matrix}\right)\right\} \left(1:n,:\right)$$.
Still working on the trivial case of induction: Now note that since Givens operations for calculation of $$\mathbf{\hat{Q}}$$ are applied pairwise to the columns of the accumulator matrix, i.e. independently for each row, we can split computation of $$\mathbf{\hat{Q}}$$ and apply it to any combination of vertical blocks of $$\left(\begin{matrix}\mathbf{Q}_{1} & \mathbf{Z}\\\mathbf{Z} & \mathbf{Q}_{2}\end{matrix}\right)$$. Let's say we decide to split it into 2 blocks with as many rows as in Q1 and Q2 and get back to block-wise formulas sought for solution of (2):
$$\mathbf{\hat{Q}_{1}=}\left[\left(\begin{matrix}\mathbf{Q}_{1} & \mathbf{Z}\end{matrix}\right)\cdot\prod_{i}\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right]\left(:,1:n\right),$$
$$\mathbf{\hat{Q}_{2}=}\left[\left(\begin{matrix}\mathbf{Z} & \mathbf{Q}_{2}\end{matrix}\right)\cdot\prod_{i}\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right]\left(:,1:n\right).$$ (3)
Let's denote those transformations in more general form as
$$\mathrm{qhat\_down}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left[\left(\begin{matrix}\mathbf{Q}_{i} & \mathbf{Z}\end{matrix}\right)\cdot\prod\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{i}\\\mathbf{R}_{j}\end{matrix}\right)\right]\left(:,1:n\right)$$
and
$$\mathrm{qhat\_up}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left[\left(\begin{matrix}\mathbf{Z} & \mathbf{Q}_{i}\end{matrix}\right)\cdot\prod\mathrm{givens\_qr}\left(\begin{matrix}\mathbf{R}_{j}\\\mathbf{R}_{i}\end{matrix}\right)\right]\left(:,1:n\right)$$
then we can rewrite (3) as
$$\mathbf{\hat{Q}}=\left(\begin{matrix}\mathbf{\hat{Q}}_{1}\\\mathbf{\hat{Q}}_{2}\end{matrix}\right)=\left(\begin{matrix}\mathrm{qhat\_down}\left(\mathbf{Q}_{1},\mathbf{R}_{1},\mathbf{R}_{2}\right)\\\mathrm{qhat\_up}\left(\mathbf{Q}_{2},\mathbf{R}_{2},\mathbf{R}_{1}\right)\end{matrix}\right)$$,
$$\mathbf{\hat{R}}=\mathrm{rhat}\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)$$
This is our solution for (2) of trivial case (z=2).
I will show solution for z=3 and then just will give the final solution without a proof.
Case z=3:
Note that functions qhat_up() and qhat_down() also implicitly produce intermediate rhat() products during their computation, so we want to 'enhance' them to capture that rhat() result as well. We will denote 'evolving' intermediate results Q and R as a sequence $$\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)$$:
$$\mathrm{qrhat\_down}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)=\left(\mathrm{qhat\_down}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right),\mathrm{rhat}\left(\mathbf{R}_{i},\mathbf{R}_{j}\right)\right)$$,
$$\mathrm{qrhat\_up}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)=\left(\mathrm{qhat\_up}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right),\mathrm{rhat}\left(\mathbf{R}_{j},\mathbf{R}_{i}\right)\right)$$.
Then, using those notations, we can write solution for (2) z=3 as
Note that algorithm for computing $$\mathbf{\hat{Q}}_i$$ requires input of Qi, iterator[(R1,R2...Rz)].
General solution for (2) for any z is built by induction as the following algorithm:

This algorithm is still sub-efficient as for the entire matrix (2) it computes more rhat() operations than needed, and can be optimized to reduce those operations when considering final solution for (1), but that's probably too many details for this post for now. Actual details are found in code and my working notes.Note that functions qhat_up() and qhat_down() also implicitly produce intermediate rhat() products during their computation, so we want to 'enhance' them to capture that rhat() result as well. We will denote 'evolving' intermediate results Q and R as a sequence $$\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)$$:
$$\mathrm{qrhat\_down}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)=\left(\mathrm{qhat\_down}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right),\mathrm{rhat}\left(\mathbf{R}_{i},\mathbf{R}_{j}\right)\right)$$,
$$\mathrm{qrhat\_up}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right)=\left(\mathbf{\tilde{Q}},\mathbf{\tilde{R}}\right)=\left(\mathrm{qhat\_up}\left(\mathbf{Q}_{i},\mathbf{R}_{i},\mathbf{R}_{j}\right),\mathrm{rhat}\left(\mathbf{R}_{j},\mathbf{R}_{i}\right)\right)$$.
Then, using those notations, we can write solution for (2) z=3 as
$$\mathbf{\hat{Q}}=\left(\begin{matrix}\mathbf{\hat{Q}}_{1}\\\mathbf{\hat{Q}}_{2}\\\mathbf{\hat{Q}}_{3}\end{matrix}\right)=\left(\begin{matrix}\mathrm{qrhat\_down}\left(\mathrm{qrhat\_down}\left(\mathbf{Q}_{1},\mathbf{R}_{1},\mathbf{R}_{2}\right),\mathbf{R}_{3}\right).\mathbf{\tilde{Q}}\\\mathrm{qrhat\_down}\left(\mathrm{qrhat\_up}\left(\mathbf{Q}_{2},\mathbf{R}_{2},\mathbf{R}_{1}\right),\mathbf{R}_{3}\right).\mathbf{\tilde{Q}}\\\mathrm{qrhat\_up}\left(\mathbf{Q}_{3},\mathbf{R}_{3},\mathrm{rhat}\left(\mathbf{R}_{1},\mathbf{R}_{2}\right)\right).\mathbf{\tilde{Q}}\end{matrix}\right)$$.
Note that algorithm for computing $$\mathbf{\hat{Q}}_i$$ requires input of Qi, iterator[(R1,R2...Rz)].
General solution for (2) for any z is built by induction as the following algorithm:
Finally, a word about how to transform solution for (2) into a solution for (1).
We can rewrite indexes in (1) as
$$\left(\begin{matrix}\left(\begin{matrix}\mathbf{Q}_{1}\\\mathbf{Q}_{2}\\\cdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{1}\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{2}\\\cdots\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}_{z}\end{matrix}\right)\mathbf{R}_{n}\end{matrix}\right)\equiv\left(\begin{matrix}\left(\begin{matrix}\mathbf{Q}_{11}\\\mathbf{Q}_{12}\\\cdots\\\mathbf{Q}_{1k}\end{matrix}\right)\mathbf{R}_{1}\\\left(\begin{matrix}\mathbf{Q}_{21}\\\mathbf{Q}_{22}\\\cdots\\\mathbf{Q}_{2k}\end{matrix}\right)\mathbf{R}_{2}\\\cdots\\\left(\begin{matrix}\mathbf{Q}_{n1}\\\mathbf{Q}_{n2}\\\cdots\\\mathbf{Q}_{nk}\end{matrix}\right)\mathbf{R}_{n}\end{matrix}\right)$$
And then regroup that into k independent tasks solving
$$\left(\begin{matrix}\mathbf{Q}_{1i}\mathbf{R}_{1}\\\mathbf{Q}_{2i}\mathbf{R}_{2}\\\cdots\\\mathbf{Q}_{zi}\mathbf{R}_{z}\end{matrix}\right)\Rightarrow\left(\begin{matrix}\mathbf{\hat{Q}}_{1i}\\\mathbf{\hat{Q}}_{2i}\\\cdots\\\mathbf{\hat{Q}}_{zi}\end{matrix}\right)\hat{\mathbf{R}}$$,
$$i\in1..k,$$
which can be solved via solution for (2).
That may also be one of parallelization strategies.
That wasn't so hard, was it? It's possible I am performing a subpar re-tracing of some existing research or method here. But I don't think there's much work about how to fit QR onto parallel batch machinery.
I hope that some horizons perhaps became a little clearer.
SSVD Command Line usage
Here's the doc, also attached to Mahout-593. At some point wiki update is due. When we know what it is all good for.
Also, from my email regarding -s parameter:
Also, from my email regarding -s parameter:
There are 2 cases where you might want to adjust -s :
1 -- if you running really huge input that produces more than 1000 or
so map tasks and/or that is causing OOM in some tasks in some
situations. It looks like your input is far from that now.
2 -- if you have quite wide input -- realistically more than 30k
non-zero elements in a row. The way current algorithm works, it tries
to do blocking QR of stochastically projected rows in the mappers
which means it needs to read at least k+p rows in each split (map
task). This can be fixed and i have a branch that should eventually
address this. In your case, if there happen to be splits that contain
less than 110 rows of input, that would be the case where you might
want to start setting -s greater than DFS block size (64mb) but it has
no effect if it's less than that (which is why hadoop calls it
_minimum_ split size). I don't remember hadoop's definition of this
parameter, i think it is in bytes, so that means you probably need to
specify something like 100,000,000 to start seeing decrease in number
of the map tasks. But honestly i never tried this yet since i never
had input wide enough to require this.
Saturday, March 26, 2011
Streaming QR decomposition for MapReduce part II: Bottom-up divide-and-conquer overview
Collecting Q: Divide-And-Conquer: a tad more details
As I mentioned before, outer QR step is essentially bottom-up n-indegree Divide-And-Conquer algorithm.
\[\mathbf{Y}=\left(\begin{matrix}\cdots\\\mathbf{Y}_{i}\\\mathbf{Y}_{i+1}\\\mathbf{Y}_{i+2}\\\cdots\end{matrix}\right)=\begin{matrix}\cdots\\\left.\begin{matrix}\mathbf{Q} & \mathbf{R}\\\mathbf{Q} & \mathbf{R}\\\cdots & \cdots\\\mathbf{Q} & \mathbf{R}\end{matrix}\right]\\\\\left.\begin{matrix}\mathbf{Q} & \mathbf{R}\\\mathbf{Q} & \mathbf{R}\\\cdots & \cdots\\\mathbf{Q} & \mathbf{R}\end{matrix}\right]\\\\\left.\begin{matrix}\mathbf{Q} & \mathbf{R}\\\mathbf{Q} & \mathbf{R}\\\cdots & \cdots\\\mathbf{Q} & \mathbf{R}\end{matrix}\right]\\\cdots\end{matrix}\Rightarrow\begin{matrix}\cdots\\\left.\begin{matrix}\cdots & \mathbf{\cdots}\\\left.\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}\end{matrix}\right] & \mathbf{R}\\\\\left.\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}\end{matrix}\right] & \mathbf{R}\\\\\left.\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}\end{matrix}\right] & \mathbf{R}\\\cdots & \cdots\end{matrix}\right]\\\cdots\end{matrix}\Rightarrow\cdots\Rightarrow\begin{matrix}\left.\begin{matrix}\mathbf{\cdots}\\\mathbf{\hat{Q}}\\\mathbf{\hat{Q}}\\\cdots\\\mathbf{\hat{Q}}\\\\\mathbf{\hat{Q}}\\\mathbf{\hat{Q}}\\\cdots\\\mathbf{\hat{Q}}\\\\\mathbf{\hat{Q}}\\\mathbf{\hat{Q}}\\\cdots\\\mathbf{\hat{Q}}\\\cdots\end{matrix}\right] & \hat{\mathbf{R}}\end{matrix}\]
The way generalized Givens thin QR works, it applies a number of Givens transformations on a Q-accumulator matrix given some initial tall matrix (in this case, Y blocks) until the tall matrix is reduced to a form of $\left(\begin{matrix}\mathbf{R}\\\mathbf{Z}\end{matrix}\right)$ , where Z has all zero elements and R is an upper-triangular. Initial value for Q-accumulator matrix is chosen as I (square identity matrix). To tranform result to a 'thin' QR result, only first n columns of accumulator are taken (that becomes Q of the decomposition) and R part is taken as the second matrix of the thin decomposition.In our case, in order to enable Givens recursive use, we generalize standard Givens algorithm by making it accept two parameters: pre-existing 'thick qr' Q accumulator instead of I (in reality only shifting 'thin' Q accumulator is sufficient) and the tall input matrix as second input.
Bottom-up divide-and-conquer algorithm hence can be described as follows:
- First, we split all input (Y) into vertical blocks (see illustration above). For each block, we compute slightly modified version of standard Givens QR which is optimized for sequential (streaming) access to the tall input block elements without running into big memory requirements. The output of this step is bunch of (Q,R) pairs (each pair corresponds to the original block). For benefit of subsequent step, we will consider this block data as ({Q}, R) where sequence of Q blocks is denoted as {Q} and contains only one matrix. (Actually math stuff normally uses parenthesis () to distinguish sequences from sets, but I feel using {} notation is much more expressive in this case).
- Second, we group the input of form {Q}, R into new groups, each group thus would be denoted as {{Q},R} such that number of R in each group doesn't exceed certain maximum bottom-up indegree limit N (usually 1000 for 1G RAM solvers).
- Third, for each group formed in step 2 above, we run row-wise Givens solver, which produces ("merges") a valid Givens solution for each group {{Q},R} → {Q},R. Essentually this solves "QR reduction" at nodes of divide-and-conquer:
,which is essentially equivalent to solving a number of individual block-wise QR decompositions over a one ore more initial blocks of Y into single oneThis algorithm is called 'compute QHatSequence2' (I think) in my detailed notes and is the one that builds by induction. Hat sign is to denote final QR blocks. I plan to discuss details of that algorithm in "part III" of this blog..
- Fourth, we consider each result of step 3 to form a sequence again and restart form step 2 and repeat it from there unless the number of groups is 1, which would produce our final Q blocks and single R as a result.
- We can consider the iterations above from the point of view of individual block Yi as a set of isolated parallel steps. We can view the entire computation as a series of independent computations over Qi,{R1...Rn}. It also turns out we always consume the sequence of R in the same order and never have to load more than one upper triangular matrix in the memory, so the parameters of such algorithms can actually be [Qi, iterator{R1...Rn}]. The algorithm produces new version of Q block, and the last solver in a group would produce a new R item for the next step R-sequence (as can be demonstrated further on). Then solver is reloaded with next R sequence and runs again (until we are left with just one R). That would be next map-only job run but each run reduces total number of Rs thousands of times. so 3 map-only runs can handle 1 billion blocks (besides the last run is really combined with the next step, computation of $\mathbf{B}^{\top}$, so we save at least one iteration setup overhead here.
- Another small enhancement is that it turns out each Q computation doesn't need entire {R1...Rn}. Let's rewrite Q block indexes into 2-variable index to reflect their group and subgroup indices:\[\left(\begin{matrix}\left(\begin{matrix}\mathbf{Q}_{1}\\\mathbf{Q}_{2}\\\cdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{1}\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}\end{matrix}\right)\mathbf{R}_{2}\\\cdots\\\left(\begin{matrix}\mathbf{Q}\\\mathbf{Q}\\\cdots\\\mathbf{Q}_{z}\end{matrix}\right)\mathbf{R}_{n}\end{matrix}\right)\equiv\left(\begin{matrix}\left(\begin{matrix}\mathbf{Q}_{11}\\\mathbf{Q}_{12}\\\cdots\\\mathbf{Q}_{1k}\end{matrix}\right)\mathbf{R}_{1}\\\left(\begin{matrix}\mathbf{Q}_{21}\\\mathbf{Q}_{22}\\\cdots\\\mathbf{Q}_{2k}\end{matrix}\right)\mathbf{R}_{2}\\\cdots\\\left(\begin{matrix}\mathbf{Q}_{n1}\\\mathbf{Q}_{n2}\\\cdots\\\mathbf{Q}_{nk}\end{matrix}\right)\mathbf{R}_{n}\end{matrix}\right).\] It turns out that computation over Q1i and Q2i requires entire {R1...Rn} but computation over Q3i requires $\left\{ \mathrm{GivensQR}\left[\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right].\mathbf{R},\mathbf{R}_{3}...\mathbf{R}_{n}\right\}$, i.e only n-1 upper-triangulars. Going on, сomputation over Q4i requires sequence $\left\{ \mathrm{GivensQR}\left[\left(\begin{matrix}\mathrm{GivensQR}\left[\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\end{matrix}\right)\right].\mathbf{R}\\\mathbf{R}_{3}\end{matrix}\right)\right].\mathbf{R},\mathbf{R}_{4}...\mathbf{R}_{n}\right\}$. And so on, with the Qn requiring only two upper-triangular arguments. That means that we quite legally can split computation into at most k independent jobs, each i-th parallel job computing blocks Q1i, Q2i...Qni in sequence while also reducing R sequence per above. To aid parallelization even more, we can actually choose k to be whatever we want: inside the algorithm, matrix $\left(\begin{matrix}\mathbf{Q}_{i1}\\\mathbf{Q}_{i2}\\\cdots\\\mathbf{Q}_{ik}\end{matrix}\right)$ is only ever transformed by applying column-wise Givens operations and horizontal shifts. Hence, it doesn't matter how it is being split into blocks, we can regroup rows there in any way to come up with a degree of parallelism k we are comfortable with.

Looks pretty complicated, huh? I guess it's not most complicated part yet though. Besides, I haven't implemented bottom-up approach 100% yet. I only implemented 2-step hierarchy (i.e. we can have n×n Y blocks initially only). I think it is kind of enough for what my company does, but it can be worked on to insert more steps in between to enable as many blocks as we want.
We've just started on the path uphill.
Saturday, February 19, 2011
Streaming QR decomposition for MapReduce part I: Induction, Divide-and-conquer and other aging but still neat goodies
One of most prominent challenges in my stochastic SVD contribution to Mahout was low-memory parallelizable implementation of a QR decomposition. Although current implementation of QR decomposition is rather tightly coupled with and rather specific for the SSVD method, it can be re-worked to be a massive scale QR method standing on its own.
Briefly, my solution is equivalent to one giant row-wise Givens solver. The trick is to legally reorder Givens operations and distribute their computations to parallel running pipelines so that most of the work doesn't require bulk data recombination.
There are several design patterns and principles used.
Streaming preprocessors
One principle I used was nested streaming preprocessors. Imagine having a bunch of lexical preprocessors working on a program source. First preprocessor strips out comments, second preprocessor parses grammar alphabet, etc. This pattern allows to cram a lot of logic in one sequential processing pass without having to load 'the whole thing' into memory.
So I tried to follow the same principle in matrix processing pipeline. First step is to produce matrix Y. We consume matrix A but we never even form so much as a complete row of A in memory. This is one of the enhancements, being able to consume A in element-by-element fashion (only non-zero elements for sparse data). We can accumulate row of Y as (k+p) long dot-product accumulator and that's all the memory this particular preprocessor needs. Once we finished with all alements in row of A, the dot-product accumulator contains final row of Y which is then passed on onto first step of QR pipeline.
We start off QR pipeline by dividing matrix Y into z horizontal blocks.
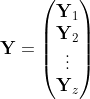
This is basically all that happens in MapReduce QR: mappers are running one or more QR blocks, optionally merging them; and then another pass goes up one level on divide-and-conquer hierarchy tree, and then the whole routine repeats until we are left with just one R.
Induction for collecting Q
Producing (and merging) Q is somewhat more complicated to describe than producing R. But the whole approach of bottom-up ~1000-indegree divide-and-conquer (or perhaps merge-and-conquer :) is the same as described in the previous section even as we evolve Q blocks thru the merge hierarchy. The algorithm for individual step of Divide-and-Conquer bottom-up iteration there builds by induction and is described in my notes. The challenge is to stream individual Q blocks through series of Givens rotations that eventually it would have to go through in order to become a block of the final Q matrix. The algorithm builds for a trivial case of induction for a single bottom-up divide-and-conquer step of indegree 2 and 3 and then proceeds with building general case of indegree n. Memory requirements are to hold one Q block in addition to R sequence during Q merging. If one merge-up is one map-only MapReduce jobs, then just two map-only MR jobs can merge up 1,000,000 blocks or more than a billion rows (assuming Y blocks can be at least 1000 rows high -- but they can be much more in practice).
Turns out the number of Givens operations that we need to apply at each evolution of Q-block can be significantly smaller than the number elements of Q block we need to apply them to because it doesn't depend on the height of the Q-block but only proportional to indegree of the bottom-up divide-and-conquer pass and also ~(k+p)/2. That basically means that we could perform each pass of divide-and-conquer as a map-only pass with Givens operations being a side file information. (actually Givens operations are produced from that stack of Rs shown above, but they are different for each Q block, so that stack of Rs is the side information and Givens are produced on-the-fly). There are also some optimization techniques to transform (reduce) R-stack as we progress thru Q blocks to avoid unnecessary computations, so at the end we end up with only one R in the stack which also happens to be final R for the local step of divide-and-conquer bottom-up process. We take the final R and use that in subsequent divide-and-conquer merge-ups.
In practice in Stochastic SVD we piggyback on the mappers of the second job to finish QR merging -- and then pass it on onto whatever second job is really supposed to do (computing matrix B). That practically would allow to achieve QR per my previous estimate of 1 billion or more rows in mappers with 1Gb RAM with what seems like practically a single map-only pass over input data. (A patch enabling preprocessing input vectors is not part of Mahout patch -- not yet at least, so Mahout version may have significantly higher RAM requirements and longer running time due to GC thrashing than my github branches if the input contains rather wide and dense vector data.)
So, to recap, the major design principles in MR-based QR were: streaming preprocessors; recursive bottom-up divide-and-conquer; design by induction. Big thanks to Udi Manber and his books on algorithm design basics that got pretty well imprinted in the inner side of my skull.
Briefly, my solution is equivalent to one giant row-wise Givens solver. The trick is to legally reorder Givens operations and distribute their computations to parallel running pipelines so that most of the work doesn't require bulk data recombination.
There are several design patterns and principles used.
Streaming preprocessors
One principle I used was nested streaming preprocessors. Imagine having a bunch of lexical preprocessors working on a program source. First preprocessor strips out comments, second preprocessor parses grammar alphabet, etc. This pattern allows to cram a lot of logic in one sequential processing pass without having to load 'the whole thing' into memory.
So I tried to follow the same principle in matrix processing pipeline. First step is to produce matrix Y. We consume matrix A but we never even form so much as a complete row of A in memory. This is one of the enhancements, being able to consume A in element-by-element fashion (only non-zero elements for sparse data). We can accumulate row of Y as (k+p) long dot-product accumulator and that's all the memory this particular preprocessor needs. Once we finished with all alements in row of A, the dot-product accumulator contains final row of Y which is then passed on onto first step of QR pipeline.
We start off QR pipeline by dividing matrix Y into z horizontal blocks.
Again, Y blocking is only conceptual, as actual blocks are never formed in one place. To put things in perspective, each map task works with one or more Y blocks.
QR pipeline works on Y rows, row by row, by applying bottom-up ordered Givens operations until it transforms Y block into the following tall matrix:
\[\mathbf{Y}_{i}\rightarrow\mathrm{GivensQR}\rightarrow\left(\begin{matrix}\times & \times & \cdots & \times & \times\\0 & \times & \cdots & \times & \times\\\vdots & \vdots & \ddots & \vdots & \vdots\\0 & 0 & \cdots & \times & \times\\0 & 0 & \cdots & 0 & \times\\\\0 & 0 & 0 & 0 & 0\\\vdots & \vdots & \vdots & \vdots & \vdots\\0 & 0 & 0 & 0 & 0\end{matrix}\right)=\left(\begin{matrix}\mathbf{R}_{i}\\\mathbf{Z}\end{matrix}\right)\]
This tall matrix is represented with an upper-triangular R matrix, which is (k+p)×(k+p) sitting on the top of tall zero matrix Z. The R matrix is the one from thin QR decomposition, and we can get rid of Z matrix as having no information.
In fact, our QR preprocessor only keeps R-sized (k+p)×(k+p) buffer which "slides" up until it ends up holding R. Each additional iteration "builds" 1 row of Y on top of buffer, turning it into something resembling upper Hessenberg form, and then second part of iteration eliminates "subdiagonal" by applying Givens iterations and turning it back to upper-triangular. Last row is then completely zeroed and thrown away (or rather, reused as buffer for Y row so we don't incur java GC thrashing too much).
Divide and Conquer
The next step is to merge blockwise QR results into single final QR result. in order to do that, we can stack up individual blockwise R matrices one on top of another and apply same strategy, namely, selectively reordered Givens set until we end up with R/Z result again:
\[\left(\begin{matrix}\mathbf{R}_{1}\\\mathbf{R}_{2}\\\cdots\\\mathbf{R}_{n}\end{matrix}\right)\rightarrow\mathrm{GivensQR}\rightarrow\left(\begin{matrix}\mathbf{R}\\\mathbf{Z}\end{matrix}\right)\]
The result of this is final QR decomposition (or at least R part of it).
The next notion is that we can apply those two steps recursively in bottom-up divide-and-conquer fashion to merge as many intermediate QR blocks as we want.
Induction for collecting Q
Producing (and merging) Q is somewhat more complicated to describe than producing R. But the whole approach of bottom-up ~1000-indegree divide-and-conquer (or perhaps merge-and-conquer :) is the same as described in the previous section even as we evolve Q blocks thru the merge hierarchy. The algorithm for individual step of Divide-and-Conquer bottom-up iteration there builds by induction and is described in my notes. The challenge is to stream individual Q blocks through series of Givens rotations that eventually it would have to go through in order to become a block of the final Q matrix. The algorithm builds for a trivial case of induction for a single bottom-up divide-and-conquer step of indegree 2 and 3 and then proceeds with building general case of indegree n. Memory requirements are to hold one Q block in addition to R sequence during Q merging. If one merge-up is one map-only MapReduce jobs, then just two map-only MR jobs can merge up 1,000,000 blocks or more than a billion rows (assuming Y blocks can be at least 1000 rows high -- but they can be much more in practice).
Turns out the number of Givens operations that we need to apply at each evolution of Q-block can be significantly smaller than the number elements of Q block we need to apply them to because it doesn't depend on the height of the Q-block but only proportional to indegree of the bottom-up divide-and-conquer pass and also ~(k+p)/2. That basically means that we could perform each pass of divide-and-conquer as a map-only pass with Givens operations being a side file information. (actually Givens operations are produced from that stack of Rs shown above, but they are different for each Q block, so that stack of Rs is the side information and Givens are produced on-the-fly). There are also some optimization techniques to transform (reduce) R-stack as we progress thru Q blocks to avoid unnecessary computations, so at the end we end up with only one R in the stack which also happens to be final R for the local step of divide-and-conquer bottom-up process. We take the final R and use that in subsequent divide-and-conquer merge-ups.
In practice in Stochastic SVD we piggyback on the mappers of the second job to finish QR merging -- and then pass it on onto whatever second job is really supposed to do (computing matrix B). That practically would allow to achieve QR per my previous estimate of 1 billion or more rows in mappers with 1Gb RAM with what seems like practically a single map-only pass over input data. (A patch enabling preprocessing input vectors is not part of Mahout patch -- not yet at least, so Mahout version may have significantly higher RAM requirements and longer running time due to GC thrashing than my github branches if the input contains rather wide and dense vector data.)
So, to recap, the major design principles in MR-based QR were: streaming preprocessors; recursive bottom-up divide-and-conquer; design by induction. Big thanks to Udi Manber and his books on algorithm design basics that got pretty well imprinted in the inner side of my skull.
 |
| My perception of LSI |
Saturday, February 12, 2011
Weathering Thru Tech Days...
 |
| One Bridge We'll Never See Again Quite The Same |
... or what is the true cost and benefit of technology
I am generally not very comfortable with making public statements on issues not directly relevant to technology and science. But I guess I need to clarify where the name of the blog comes from. Besides, it is still relevant to science and technology, albeit on a purely philosophical level.
Quite often I find myself wondering if the value/cost ratio of that flat tv on my wall is really that good as I thought it was when I struck that "submit order" button. Over the years I increasingly came to conclusion that it is not. And not in the sense that I had problems balancing my checkbook a month after when I had to put up with that credit card bill.
There's a lot of hidden costs both in future and present associated with "techno revolution" we are immersed in.
Indeed, we pay everywhere, every minute without realizing it, just for the privilege of having that Droid X in our pocket. We spend a lot of time developing something; and very often we don't enjoy the time spent. We spend time talking to people while we'd really be spending time with our kids or talking to somebody else instead. We don't get to create stuff we really like instead. Gosh, just mere thought of how much of my productive life I have spent on creating things I personally could quite easily live without, makes me sick.
And by spending all that time, we only create things that will pollute, spend energy (=pollute again, =create higher health costs), cause climate change, in other words will create even more compound future costs for our children to pay. We find it is so easy to borrow from our children, don't we? What kind of economy is that where we pay only fraction of the real cost and expect "future administrations" to pick up the deficit? What kind of human robs his kids?
And that luxury car navigation option, is it really worth not averting those couple food riots our children would have to live through?
And all that war tech?.. Better not even get me started on this...
In my opinion, very few tech products and benefits of tech revolution are actually worth their cost (their real cost, not just those virtual numbers assigned to our accounts we give away to have them).
Well, my Nikon gear may be one happy exception as sometimes I feel as if their craftsmanship helps me to work on my soul development. A little stretch, but...
 |
| A Wait By The Glass Ocean |
Though perhaps there's one redemption for having all that technological progress. Which is most (and perhaps the only) worthy product, and that's the technology itself.
Chances are our technology is just not yet "smart" enough to produce anything really useful. But it still may become that.
The hope is that at some point we could achieve an 'ubertech' which would provide benefits finally far exceeding the real cost. Like colonizing another worlds. Or keeping our planet in balance. Or transforming ourselves into completely different state of thought or biology. Reaching out to other cultures out there, after all. Who knows what else, something we can't even imagine today.
Those are uberproducts, uberbenefits, coming with a real value which is hard to underestimate. Those benefits are so uber that it doesn't really matter much how much it costs, the only that matters is that at the end of the day we still have enough to pay for them. Like a heart transplant. That hope redeems the tech and all its today's overhead. If we still will be able to afford it...
And the reason why we may not be able to afford it might be because we will have overspent on nurturing the pre-tech (such as the one we have today).
 |
| Fort Ross |
So it's a balancing act: it seems that ubertech predicates itself on pre-tech, along with its pre-benefits, pre-nonsense and pre-waste. But the more of the wasteful, nonsensical benefits we have, the more we borrow from the future capacity and jeopardize the path of reaching that cost/benefit ratio tipping point where everything caused by pre-waste could eventually be rectified and attended to.
The bottom line is, we humans, not just present, but also some past and all future generations collectively, are doing nothing else but weathering the technology as we have it today, the early tech days. Whether we will be able to bridge the gap between all the costs and future uber-benefits, is anybody's guess at this point. The danger that we over-borrow is very real. It's a blizzard and it yet remains to be seen if we can weather through it without freezing to death. I am just trying to remember that we need the pre-tech but not necessarily the product.
And whenever I work on a technology these days, I try to at least ask myself a question whether it has even a slightest chance to be a pre-tech for the 'ubertech', whether some part of it could be used in another part that could be part of another part of that eventual ubertech that delivers us.
Or it is just yet another one of those stupid dead-end buzzword technologies people use just to add a markup on the price tag for their skills.
iPad? I don't care for no stinking iPad!..
I do care, however, about the fact that somebody out there is still seeking for the next technological leap, and that gigantic evolutionary algorithm with voluntary fitness model force assigning evolutionary fitness scores expressed in dollars and pennies, pence, shillings and cents based on millions of factors.. For in the end it is all about evolution. And evolution, as we know, is all about survival. So we better not forget what it is really all about: a search for the future. No less, no more.

Subscribe to:
Posts (Atom)